Text analysis
Text analysis
Text Analysis involves examining unstructured and semi-structured text data to extract meaningful insights that inform decision-making and enhance customer satisfaction. By discerning hidden patterns, sentiments, and correlations within extensive textual data sets, Text Analytics empowers businesses to make well-informed choices.
In Do You Know, Text Analytics employs a blend of Natural Language Processing (NLP) techniques and Machine Learning to derive insights. The resulting analyses can be visualized through automatically generated charts in the Do You Know interface.
Steps to perform text analysis in Lumenore?
Step 1: After accessing “Do You Know,” select “Text Analytics.”
Step 2: Choose a Schema and click “Next.”
Note: The schema signifies the dataset for analysis. If absent, create one, ensuring prerequisites (A KPI, Date, and Attribute) are met.
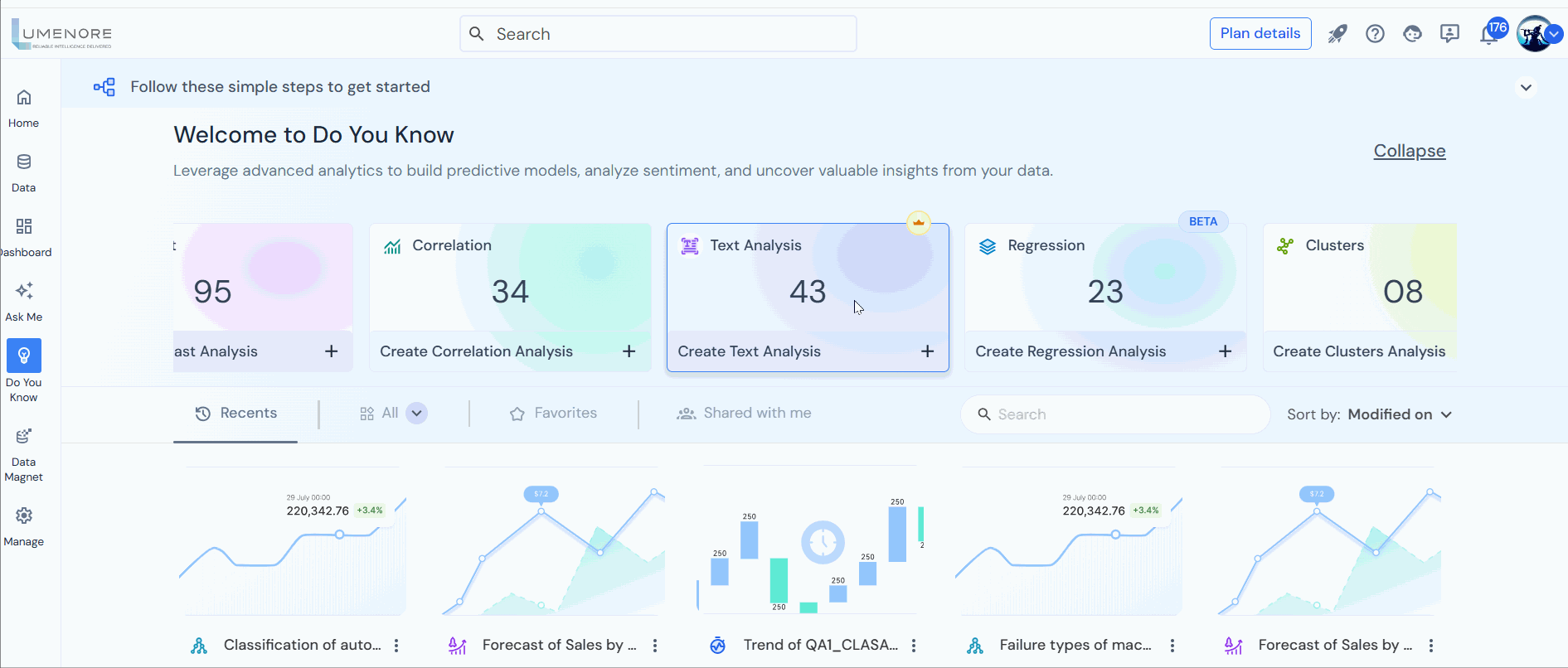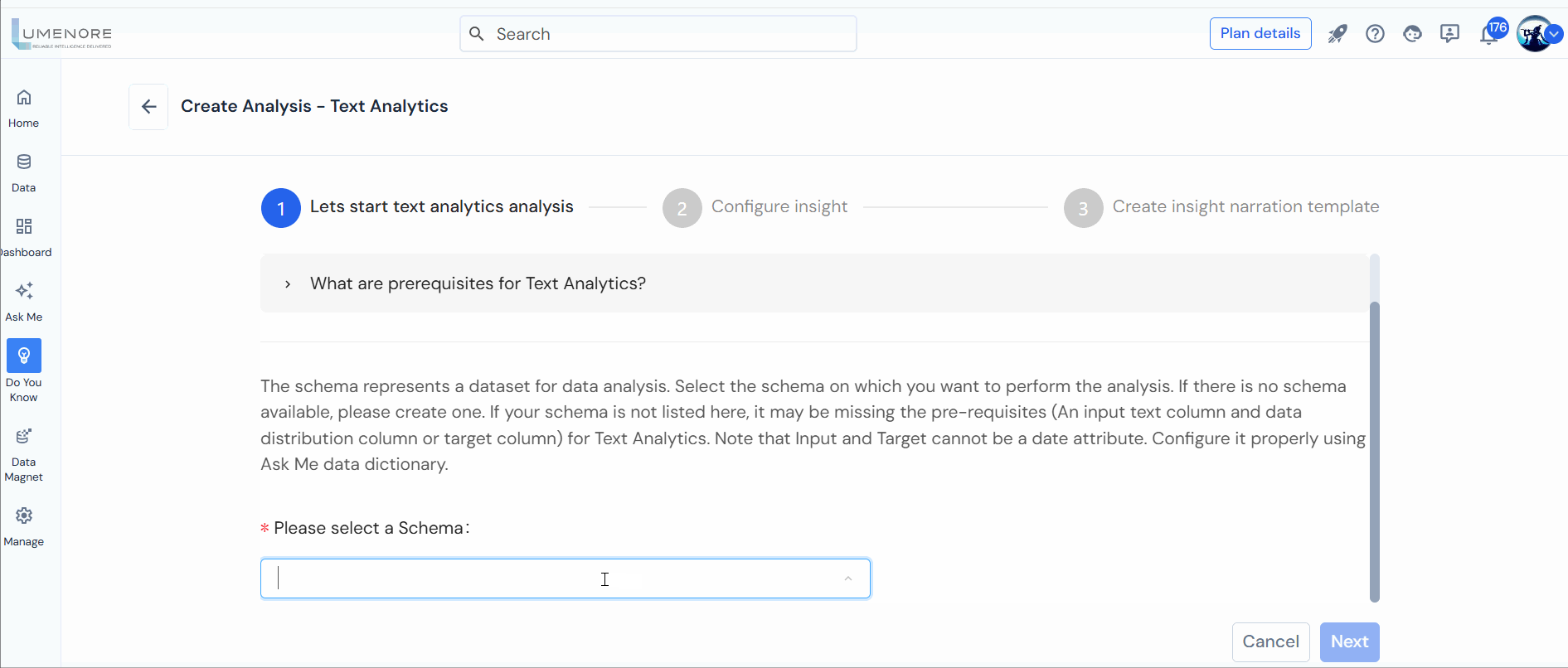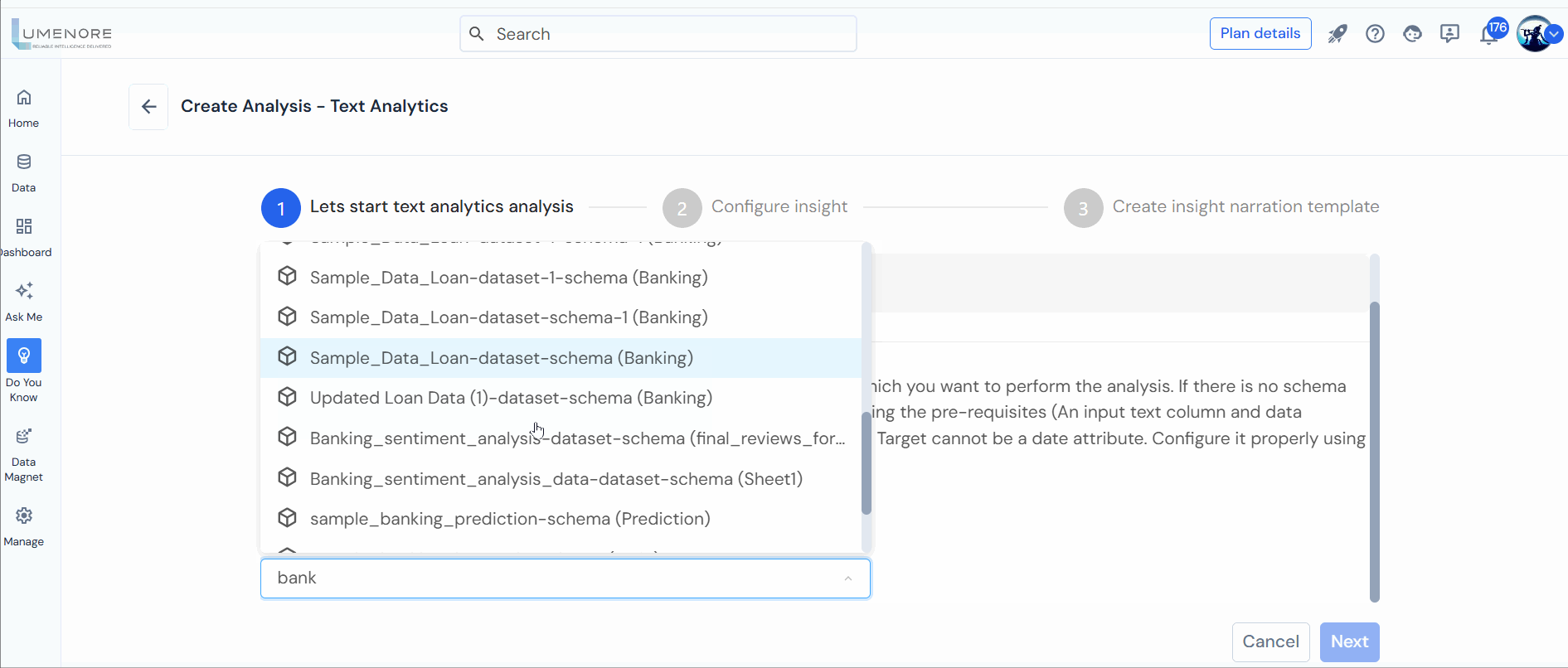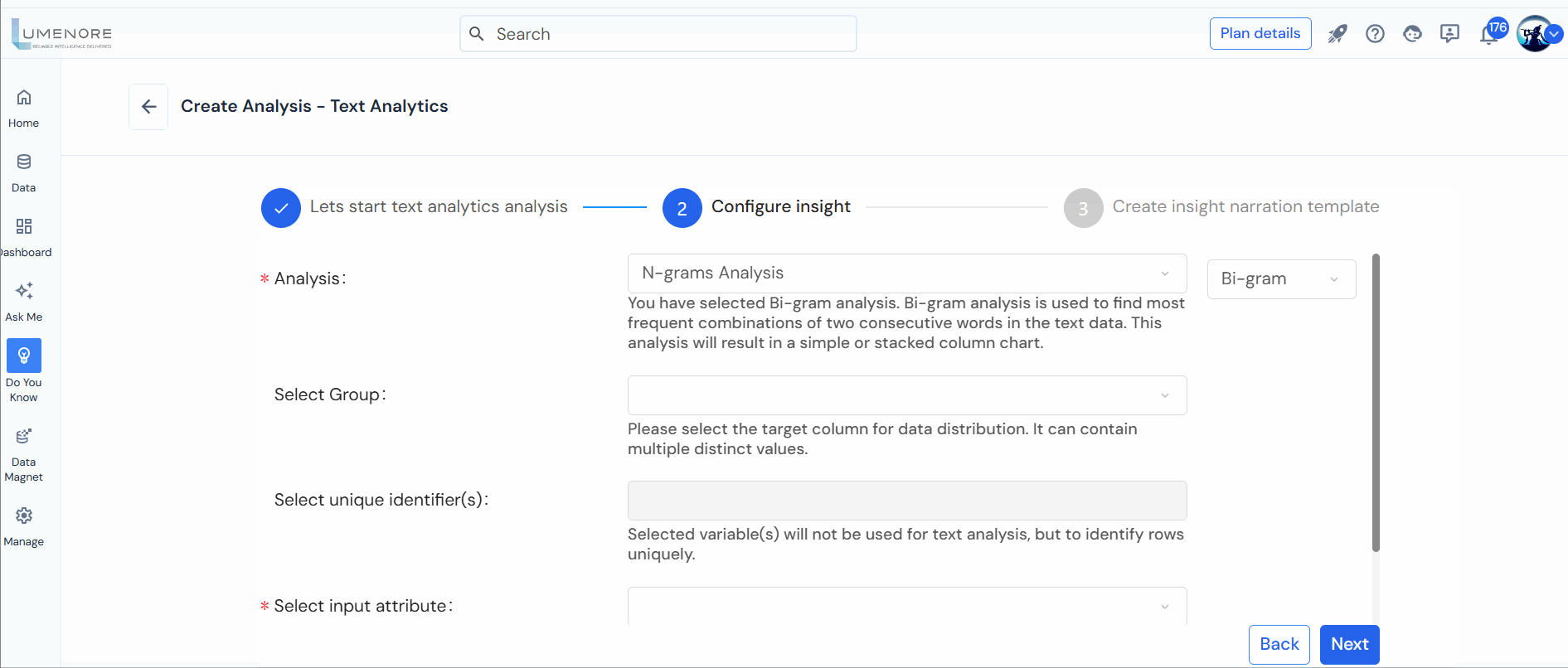
Step 3: Select the following to configure:
- Analysis: Allows users to define the desired text analysis type.
Four distinct types of analysis are supported within the Text Analytics module to suit diverse user needs:
- N-grams Analysis: This feature identifies the most prevalent words within the text, offering a broad overview. It also examines the frequency of sequences of words, such as bi-grams (two consecutive words) or trigrams (three consecutive words).
If you opt for “N-gram Analysis.” Next, in the second drop-down menu, selecting “Uni-gram” will display the most common single words. Choosing “Bi-gram” will present the most common pairs of consecutive words, while “Tri-gram” will exhibit the most frequent triplets of consecutive words, and so forth.
- Sentiment Analysis: Determining the sentiments of the text data?whether positive, neutral, or negative?is the primary aim of this analysis. Each text item is tagged with its respective sentiment.
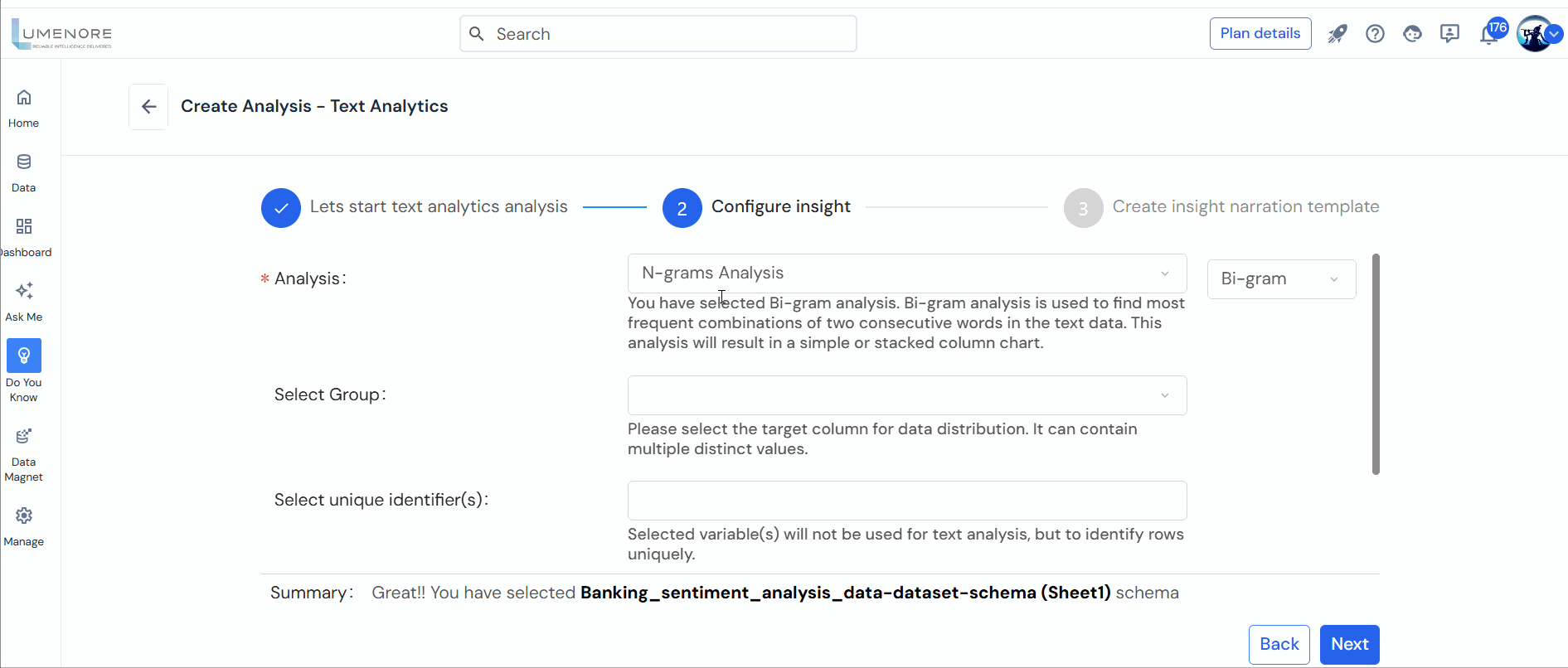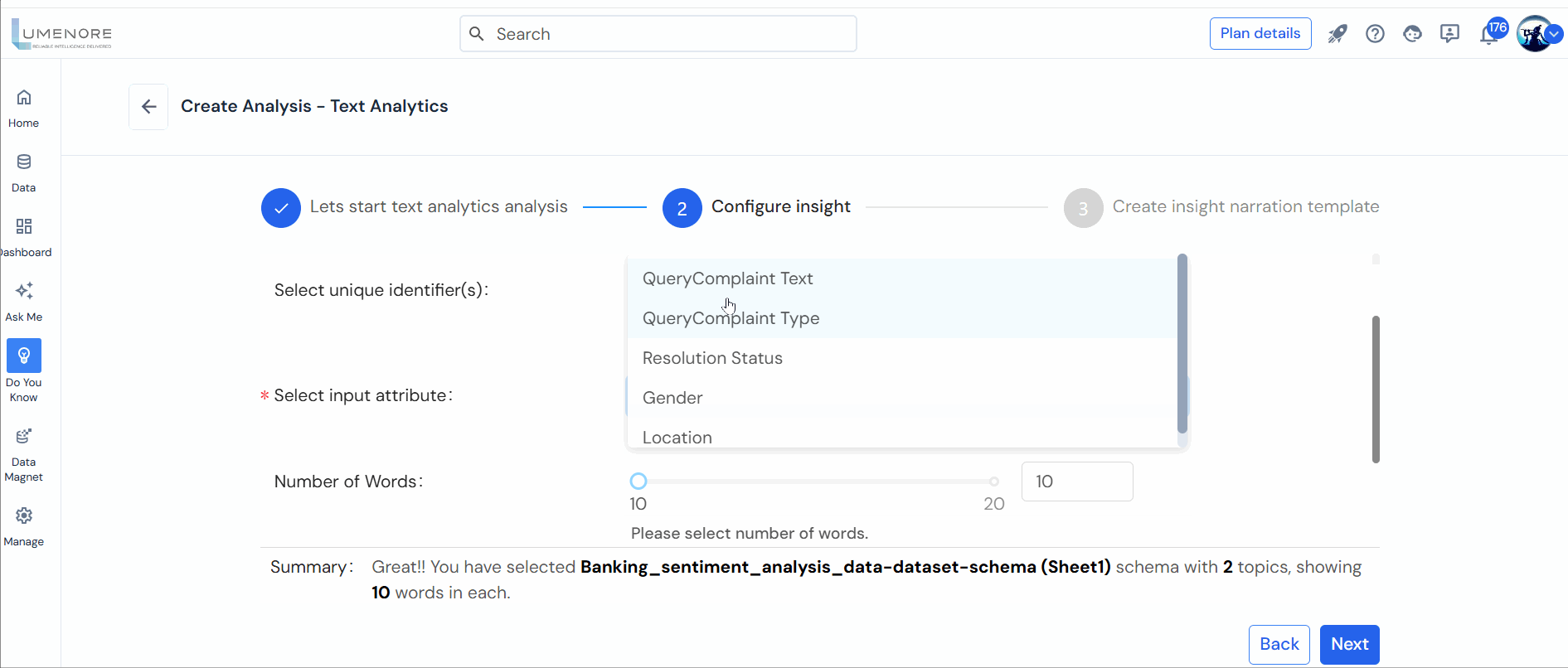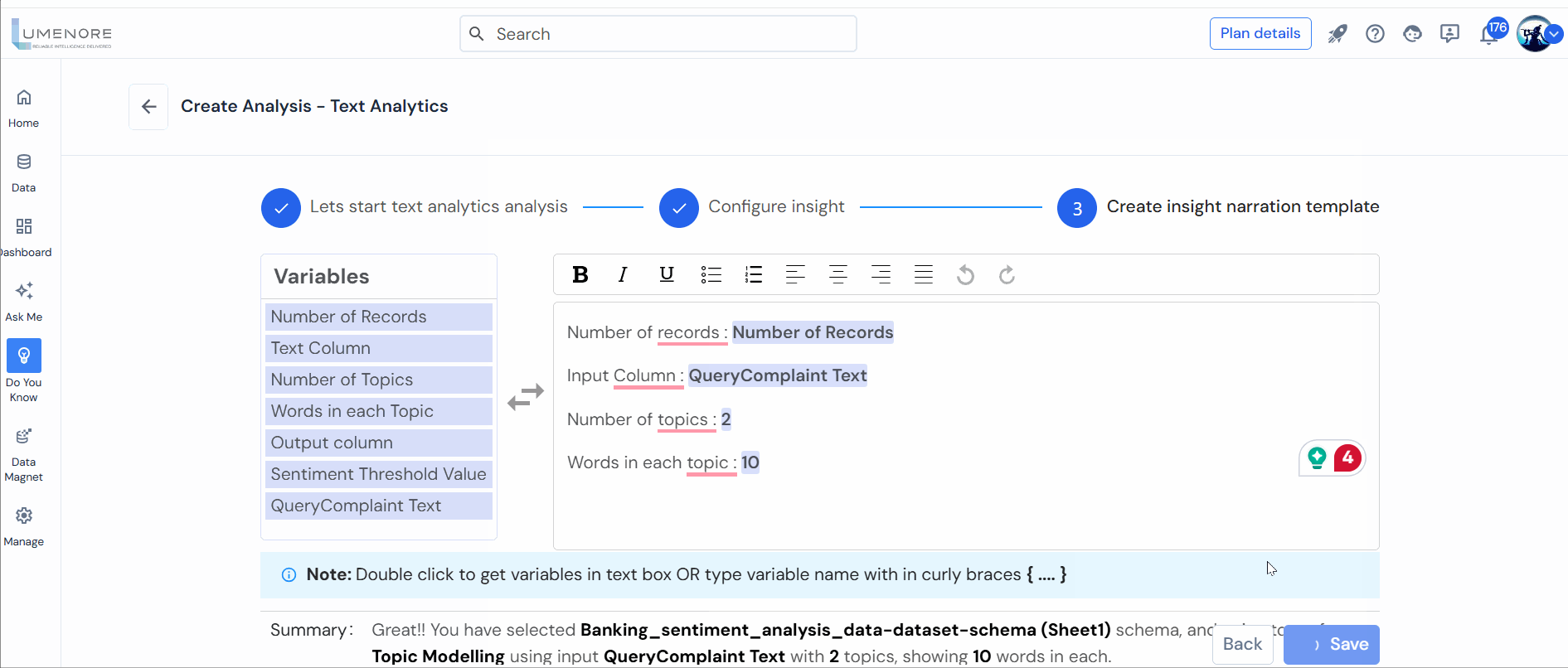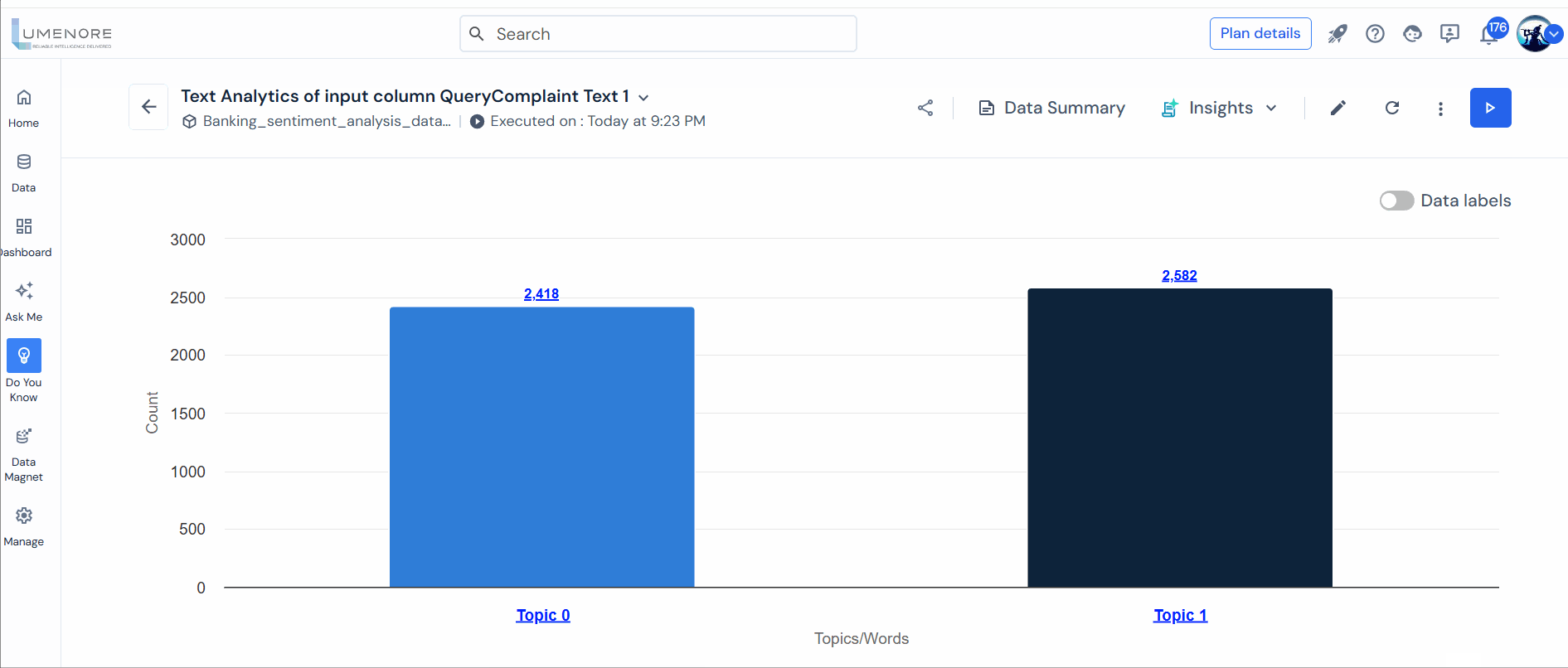
- Topic Modeling: Utilizing sophisticated Natural Language Processing, this technique automatically groups words and similar expressions that best define sets of documents. It uncovers various topics or ideas within single or multiple text documents.
- Text Classification: This feature facilitates the development of machine learning models using text data. Subsequently, these models can be leveraged to make predictions based on new textual inputs.
- Select Group: Next, users must choose the grouping criteria, which can be a categorical column in the dataset with a few distinct values.
Like when selected, the N-gram analysis will be conducted for each category or value within the chosen column. If this field remains unspecified, the N-gram analysis will be done on the complete text dataset.
For the time being, let’s leave this field blank.
- Select unique identifier(s): The chosen variable(s) will not be utilized for text analysis; rather, they will uniquely identify rows within the dataset.
- Select input attribute: This input is of the utmost significance as the column selected here will contain the text data utilized for the analysis process.
- Do you want to add filters? Optionally add filters.
- Click “Next.”
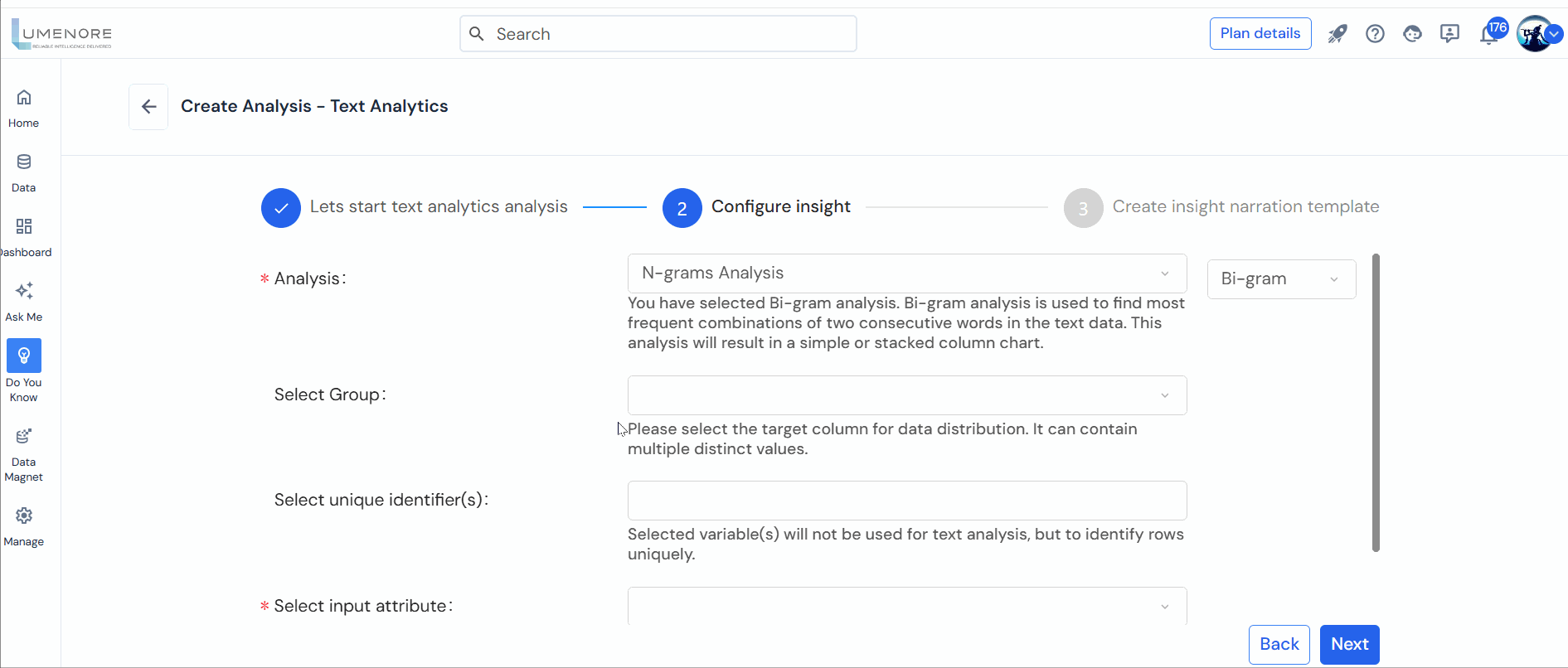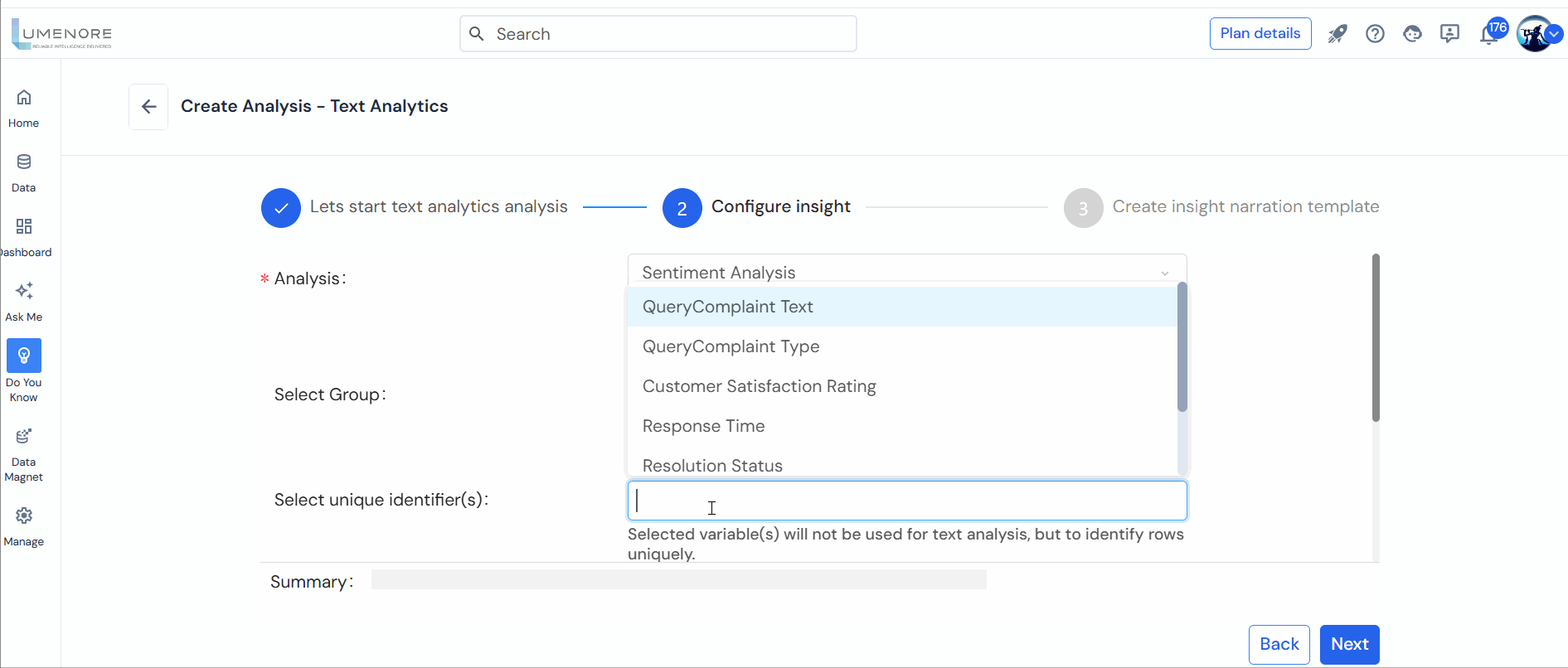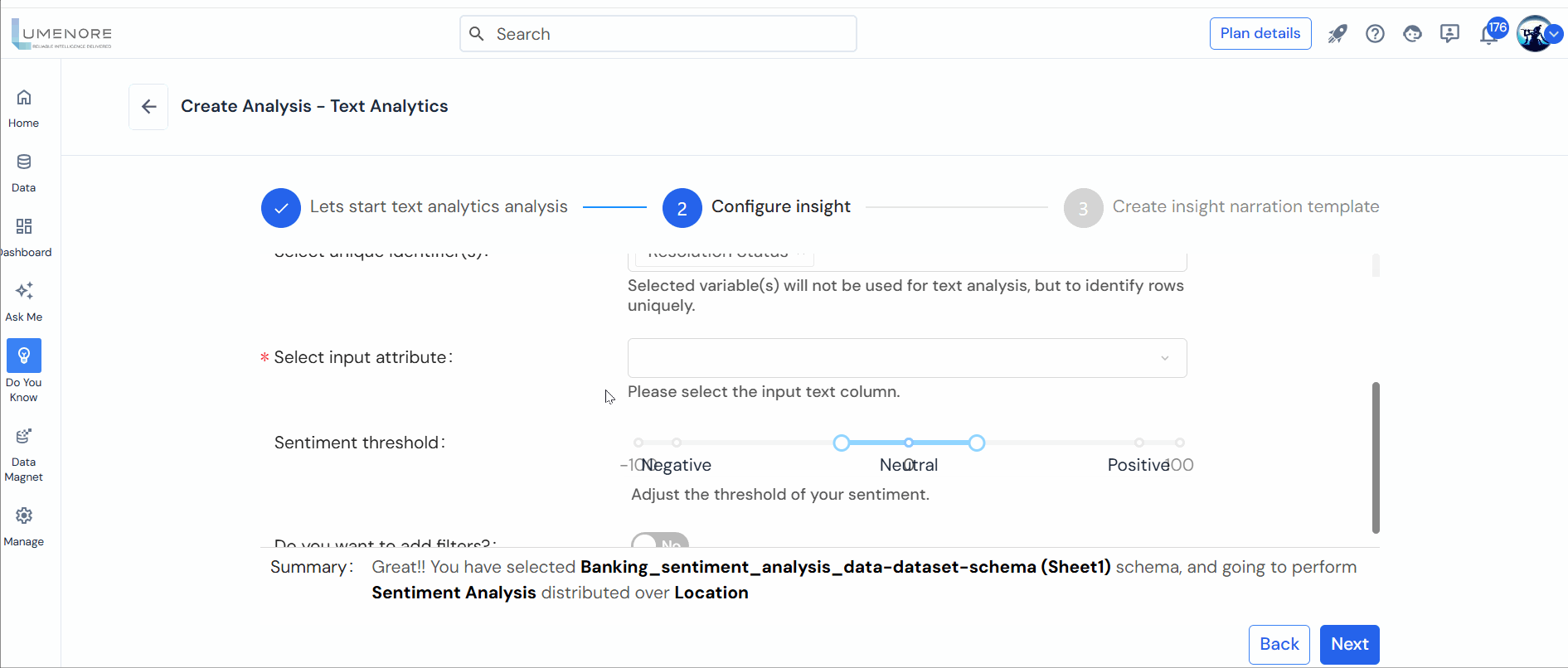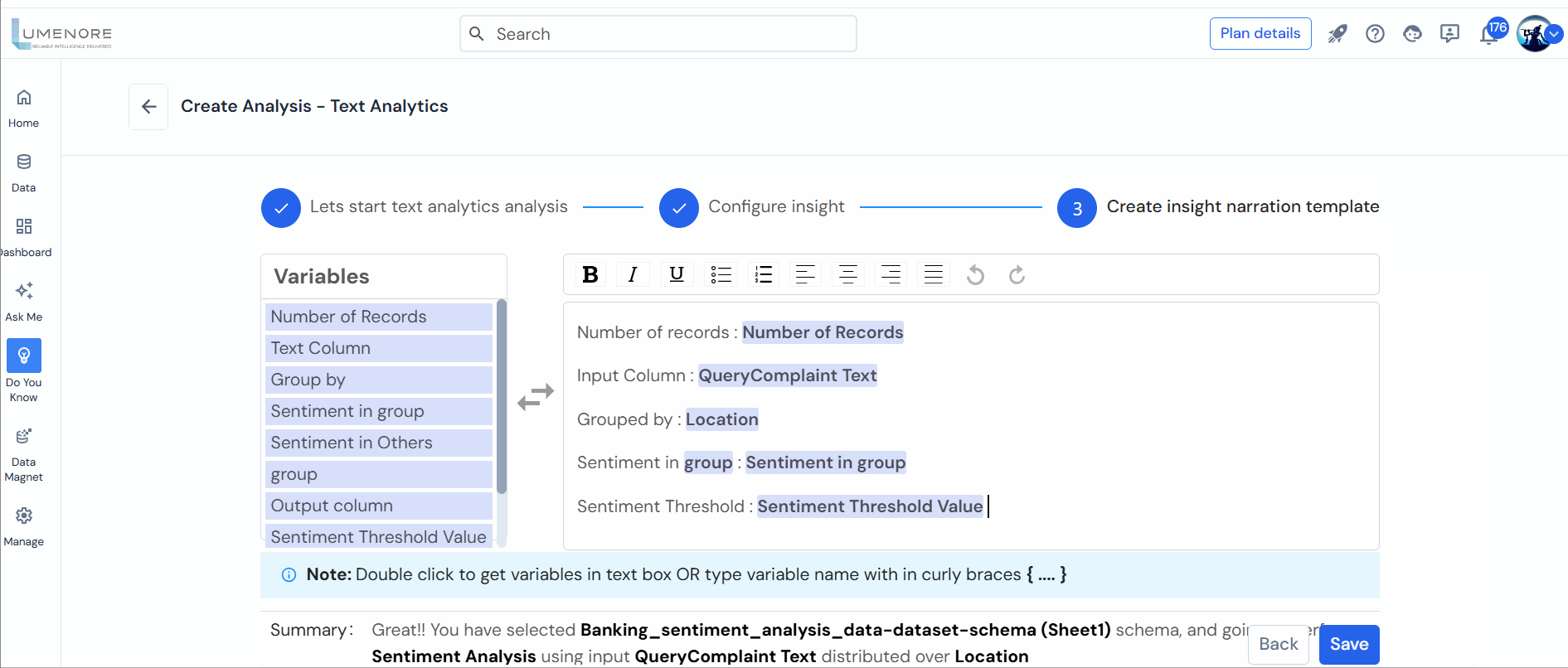
Step 4: Users can tailor the insights narrative, outlining all the variables in crafting the insight. Then, click on “Save.”
Step 5: Name the insight for future access (default suggestion provided) and save it.

Note: If you wish to apply a filter, a window for creating filters will appear. As shown in the Trend Analysis, establish filters by groups or conditions as needed.
Step 6: A new window appears; click “Execute Now” to generate insights.
Upon initiation of execution, the system will undergo four background processes. You can also terminate the execution at any point before its completion.
In the output, horizontal bars will display the percentages of positive, negative, and neutral sentiment present within the dataset.

N-grams Analysis (Bi-gram)

Text Classification

Note: You must specify your approach to insights, indicating whether you want to build a new model or predict using an existing one. Additionally, the algorithm and split ratio will be provided.
Topic Modeling
Note: In the configuration, you must specify the number of words and the topic.
