Regression analysis
Regression analysis
Regression is a machine learning technique employed to forecast the value of a target variable by analyzing one or more input variables or columns. In essence, it aids in making future predictions based on historical data.
For instance, suppose you possess a dataset on various houses, encompassing details such as their sizes and corresponding prices. Using regression, you can construct a model that takes the size of a house as input and estimates its price as output. Subsequently, this model can forecast prices for other houses, drawing from their sizes. It essentially functions as a tool that extrapolates future outcomes by drawing insights from past information. Additionally, regression can involve multiple input variables to predict values for the target variable.
To Perform Classification Analysis in Lumenore
Step 1: After accessing “Do You Know,” select “Regression.”
Step 2: Choose a Schema and proceed by clicking “Next.”

Note: The schema signifies the dataset for analysis. If absent, create one, ensuring prerequisites (A KPI, Date, and Attribute) are met.
Step 3: The user must make the following selections to configure:
- Choose the insight approach: Two options are available:
-
- Build a new machine learning model?
- Reuse already available model.
Choose the first option to construct a model. If a model has already been developed in Classification, select the second option to generate forecasts using that model.
- Select the model: This feature is disabled when building a new machine learning model, but is enabled when reusing an existing model. Once enabled, select the desired model.
- Output variable: Choose the output variable for the regression model.
- Unique Identifier(s): These selected variable(s) are not utilized for model development but serve to identify rows uniquely.
- Choose input variable(s): Please specify the input variable(s) necessary to construct the regression model.
- Algorithm Selection: Pick a classification algorithm to develop your model. Do You Know offers several widely used ML algorithms, such as:
- Linear Regression: It predicts a continuous numerical output variable based on one or more input features. Linear regression aims to find the best linear relationship between input features and output variables by assuming a linear relationship. The equation for a simple linear regression model with one input feature is y = mx + b, where y is the output variable, x is the input feature, m is the slope of the line, and b is the y-intercept.
- Decision Tree: A supervised learning algorithm for classification and regression tasks constructs a tree-like structure by recursively splitting data based on input feature values to make decisions or forecasts. It’s interpretable and handles categorical and continuous features but can be prone to overfitting with complex trees.
- Random Forest: An ensemble learning algorithm used for classification and regression involving creating multiple decision trees that combine outputs for forecasts. It mitigates overfitting by training trees on random subsets of data and features.
- XG Boost: A robust gradient-boosting framework known for high performance that constructs decision trees sequentially to correct the errors of the previous tree. It optimizes tree construction and model regularization to prevent overfitting.
- Split Ratio (Train: Test) Selection: Split ratio train test is a technique for evaluating a model’s performance. It involves dividing data into training and testing sets, using the training set for model training and the testing set for evaluating its performance. Here. We are using an 80-20 ratio.
- Add Filters (optional): Apply filters based on conditions. Here, we are using filters.
- Advance settings: This tab provides general settings, categorical input, and numerical input setting options.
In a general setting, you can remove high cardinality and low variance columns.
In categorical inputs, you can remove missing values (yes or no) and provide an encoding method (one-hot or label encoding).
In Numerical inputs, you can remove missing values and outlier removal (yes or no).

Step 4: Users can tailor the insights narrative, outlining all the variables in crafting the insight. Then, click on “Save.”
Step 5: Name the insight for future access (default suggestion provided) and save it.

Note: If you wish to apply a filter, a window for creating filters will appear. As shown in the Trend Analysis, establish filters by groups or conditions as needed.
Step 6: A new window appears; click “Execute Now” to generate insights.
Upon initiation of execution, the system will undergo four background processes. You can also terminate the execution at any point before its completion.
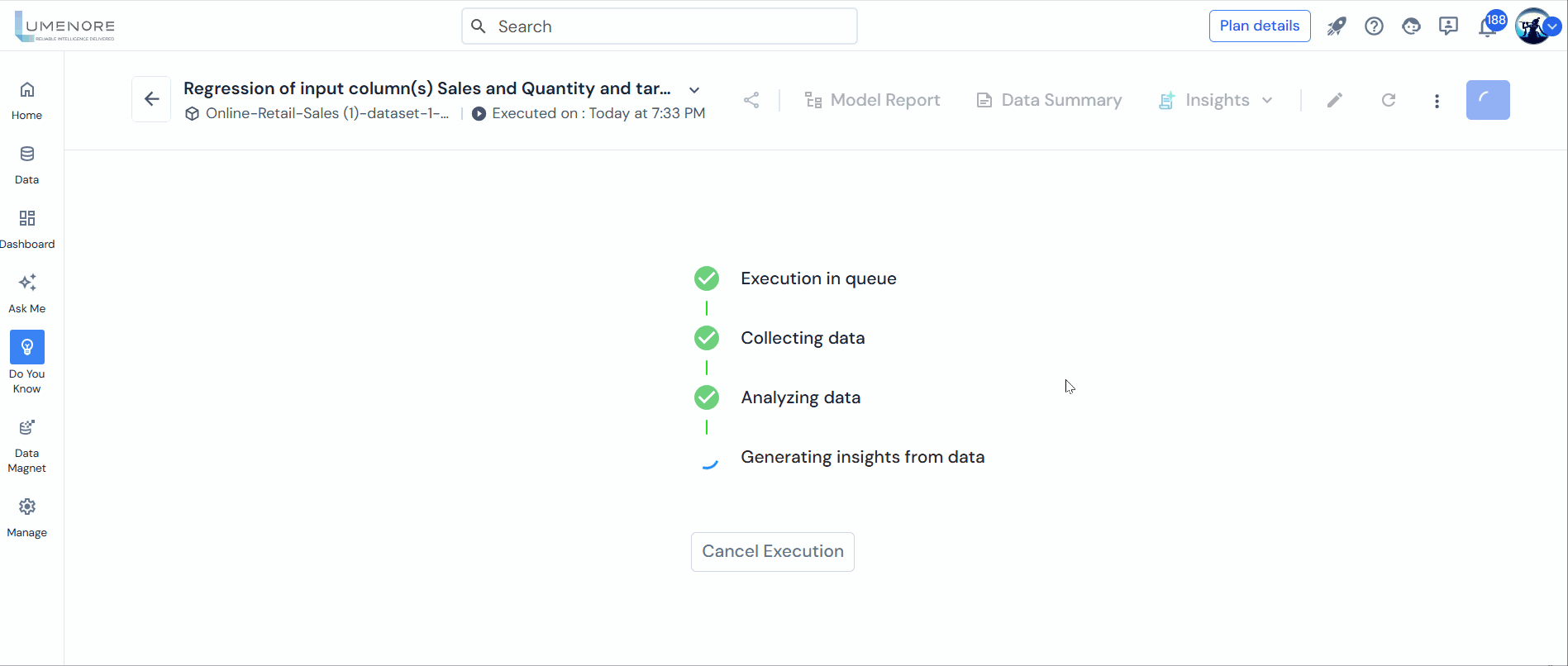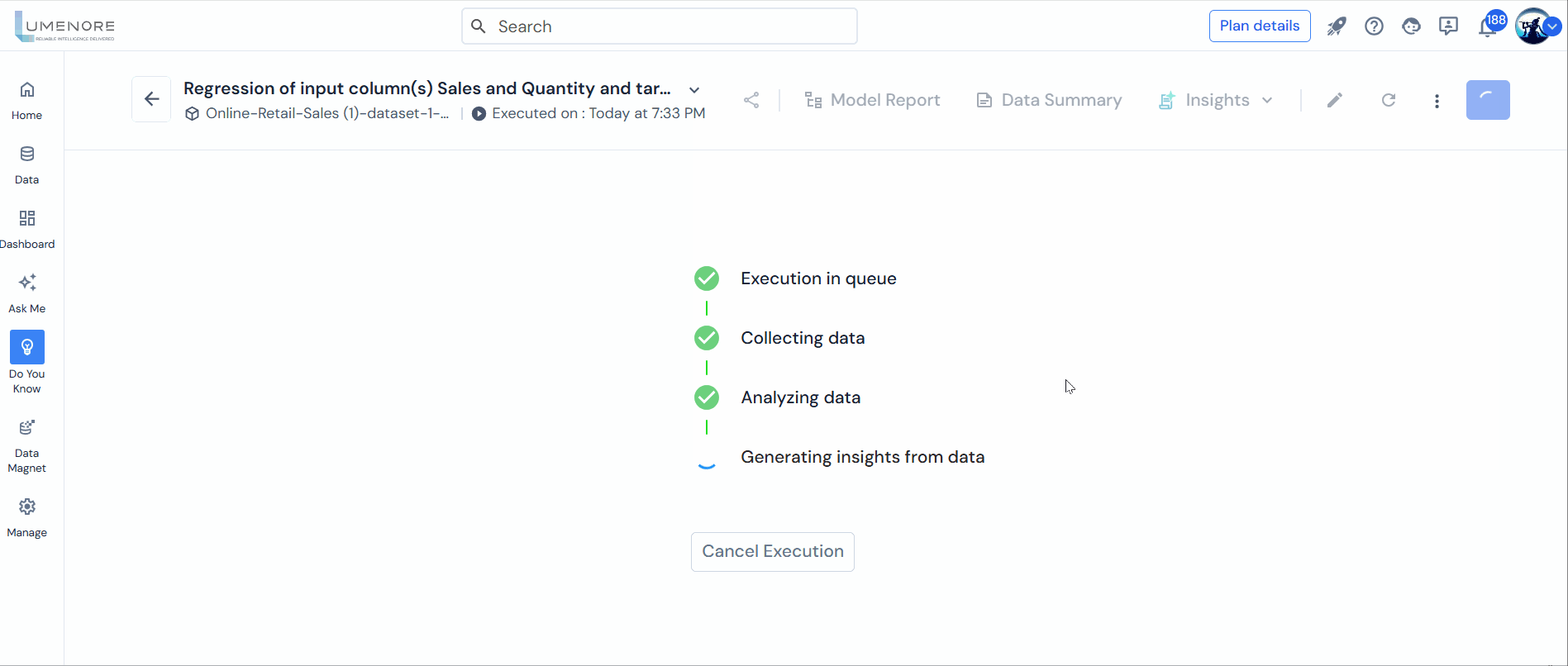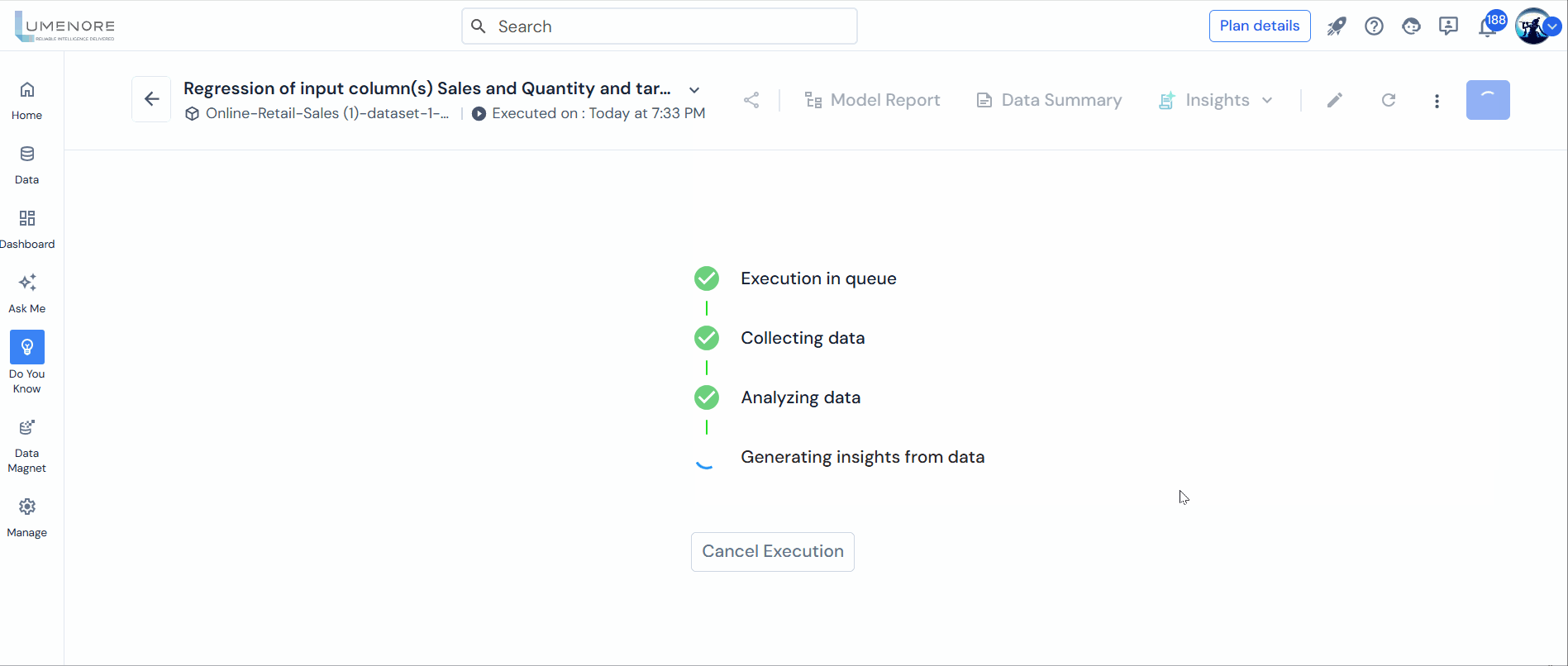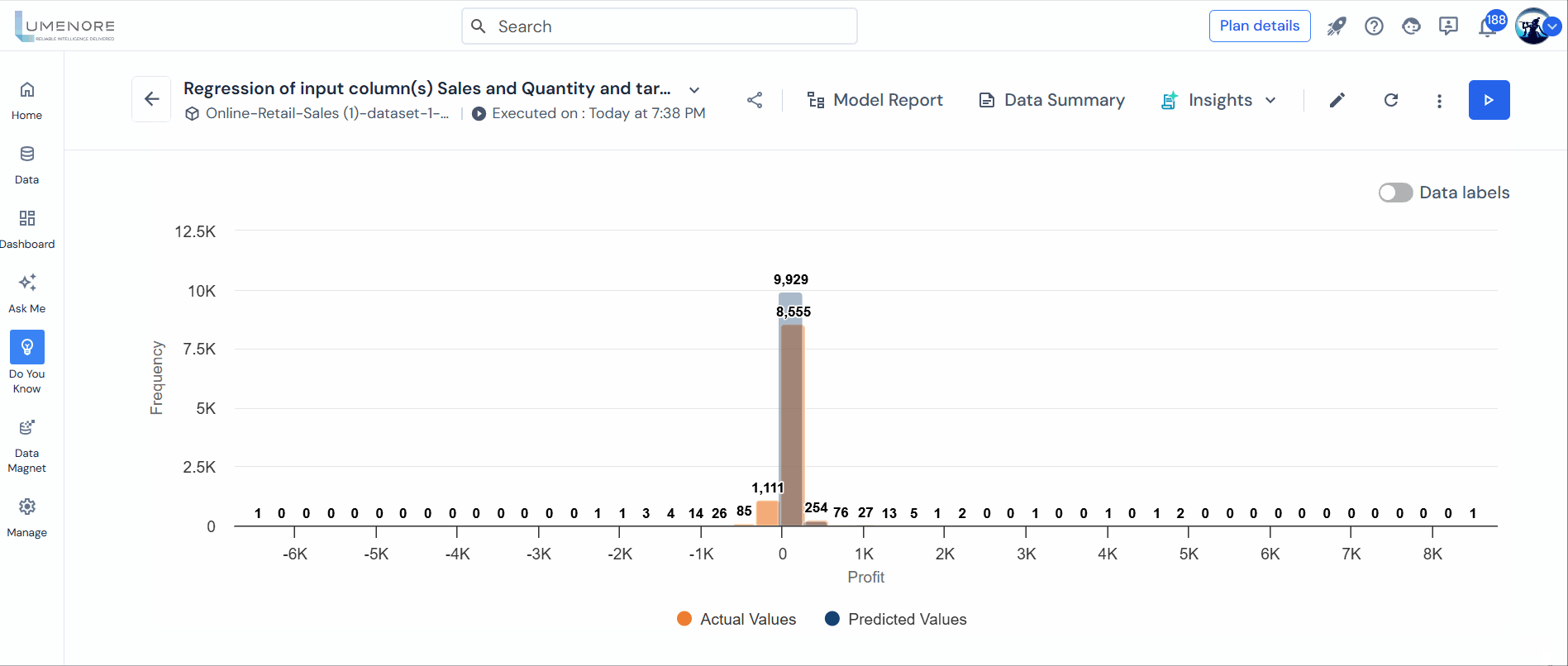
For clarity, we’ve constructed a regression model with quantity as the output variable and profit and sales as the input variables. We used linear regression as the algorithm and adopted an 80:20 training and testing split ratio (Train: Test) to analyze the relationship between profit and sales.
Case 2: Re-use already available model
Step 1: After choosing a schema, select “Reuse an existing model” in the insight approach, then select the previously created model for classification.
Click “Next.”
Step 2: Users can tailor the insights narrative, outlining all the variables in crafting the insight. Then, click on “Save.
Step 3: Name the insight for future access (a default suggestion is provided) and save it.
Step 4: A new window appears; click “Execute Now” to generate insights.

